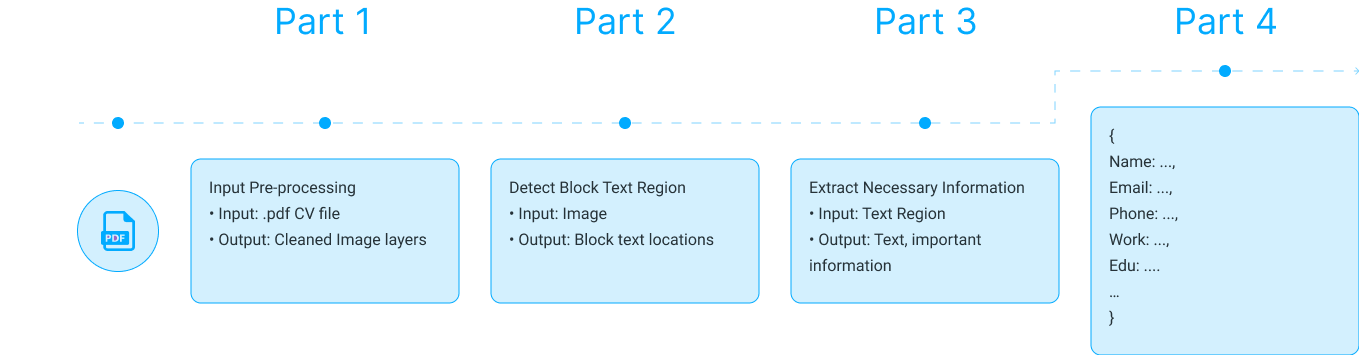
The CV Parser System is an AI-powered solution that automatically extracts important information from PDF resumes. By combining Computer Vision and Natural Language Processing, the system converts unstructured CV data into structured and usable information.
This helps businesses reduce manual work, speed up recruitment, and improve candidate screening accuracy.